
Claude Sonnet 4.6 od Anthropic: Testujemy Nowego Króla Kodowania
Gdy OpenAI świętowało premierę GPT-5.4, Anthropic działało po cichu. Bez wielkiej konferencji, bez eventu na żywo — po prostu wypuściło Claude Sonnet 4.6 i poczekało, aż rynek sam wyrobi sobie opinię. I ta opinia okazała się jednoznaczna: wśród programistów Sonnet 4.6 to numer jeden.
Dwa tygodnie intensywnych testów w realnych projektach — od prostych skryptów Pythona po złożone systemy mikroserwisów, od refaktoryzacji legacy code po debugowanie race condition na produkcji. To nie były testy syntetyczne. Oto co znaleźliśmy.
Ocena końcowa: 9.2/10
Specyfikacja i co nowego w Claude Sonnet 4.6
Architektura i parametry
Claude Sonnet 4.6, podobnie jak GPT-5.4, opiera się na architekturze Mixture of Experts — ale z innym podejściem do aktywacji parametrów i zarządzania kontekstem. Kluczową innowacją są zaawansowane mechanizmy „pamięci”, które pozwalają modelowi znacznie lepiej śledzić zależności w długich rozmowach. Jeśli 50 wiadomości temu omówiłeś architekturę projektu, Claude wciąż to pamięta i bierze pod uwagę przy każdej kolejnej odpowiedzi.
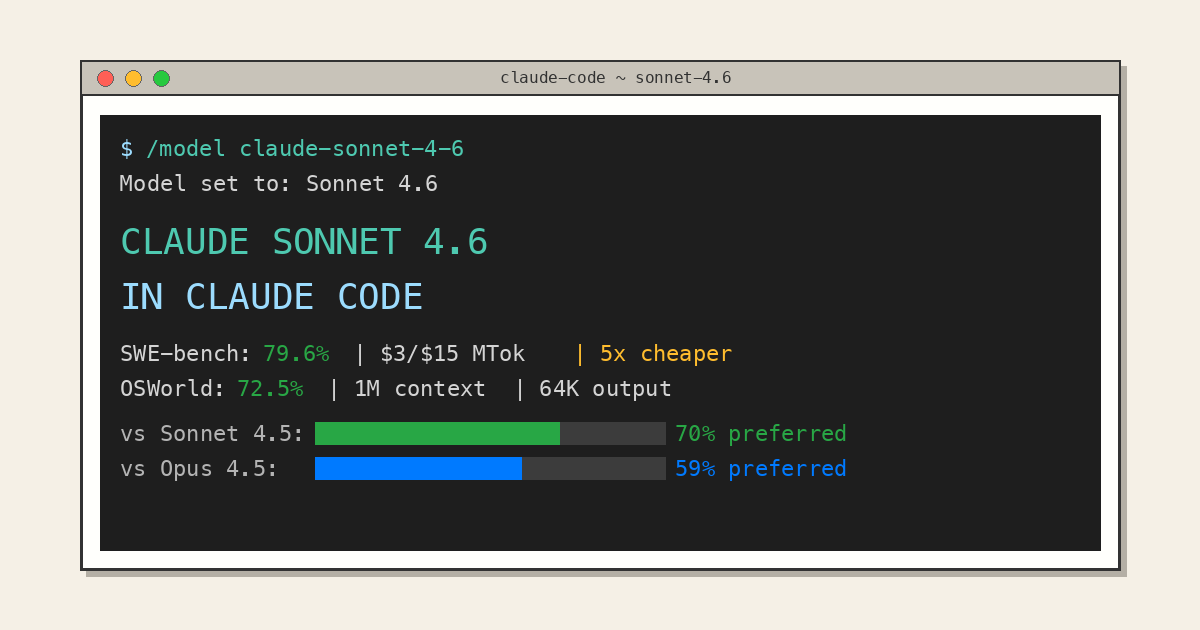
Model jest dostępny przez interfejs webowy Claude.ai, przez API Anthropic, przez integracje z IDE (Cursor, Windsurf, VS Code) oraz przez Claude Code — dedykowane narzędzie terminalowe, o którym piszemy osobno niżej.
Kluczowe zmiany od wersji 4.5
Przejście z Claude 4.5 do 4.6 to więcej niż inkrementalna aktualizacja. Cztery zmiany mają realny wpływ na codzienną pracę:
- Lepsze wsparcie dla polszczyzny — dokumentacja, komentarze i nazewnictwo zmiennych po polsku obsługiwane są na zupełnie innym poziomie niż w poprzedniej wersji
- Wbudowane narzędzia do analizy kodu — model może „zobaczyć” strukturę plików i zależności między modułami, bez konieczności ręcznego opisywania architektury
- Ulepszony tryb agentowy — Claude może samodzielnie wykonywać komendy terminalowe, oczywiście za zgodą użytkownika
- Pełniejsza integracja z Git — łącznie ze zrozumieniem historii commitów i interpretacją diffów
Testy kodowania: praktyka vs teoria
Test 1: Refaktoryzacja legacy code (PHP → PHP 8.3)
Prawdziwy scenariusz z polskiej firmy e-commerce. Moduł PHP napisany w 2018 roku — pełen technicznego długu: brak testów jednostkowych, mieszanie polskich i angielskich nazw zmiennych, bezpośrednie zapytania SQL zamiast ORM.
Zadanie: „Przeanalizuj ten kod, zidentyfikuj problemy bezpieczeństwa i antywzorce, a następnie zrefaktoryzuj go do PHP 8.3 z użyciem Doctrine ORM. Przygotuj też plan testów jednostkowych.”
Claude wykrył 7 krytycznych luk bezpieczeństwa — w tym SQL Injection i XSS — zidentyfikował 12 antywzorców z uzasadnieniem i zaproponował nową architekturę opartą na wzorcu Repository. Kod wynikowy był zgodny z PSR-12 i dobrze skomentowany. Imponujące było zrozumienie kontekstu biznesowego — model sam zauważył, że funkcja obliczZnizke() należy do osobnej klasy serwisowej, a nie do kontrolera.
| Kryterium | Ocena |
|---|---|
| Jakość kodu wynikowego | 9/10 |
| Zrozumienie kontekstu biznesowego | 10/10 |
| Czas wykonania | 4 minuty |
Test 2: Tworzenie API REST od zera (FastAPI + JWT + Docker)
Kompletne API dla systemu zarządzania zamówieniami: autentykacja JWT, role administratora i użytkownika, operacje CRUD, walidacja Pydantic, dokumentacja OpenAPI.
Zadanie: „Stwórz kompletne API z autentykacją JWT, podziałem ról i pełną dokumentacją. Użyj FastAPI, SQLAlchemy i Pydantic. Przygotuj docker-compose.”
W jednym przebiegu Claude wygenerował: pełną strukturę projektu z podziałem na moduły, modele SQLAlchemy z relacjami, schematy Pydantic, endpointy z dekoratorami autoryzacji, konfigurację JWT z refresh tokenami, docker-compose z PostgreSQL i Redis, README z instrukcją uruchomienia i przykładowe testy pytest. Jedyną korektą była drobna poprawka konfiguracji CORS — naprawiona przez model w sekundę po wskazaniu błędu.
| Kryterium | Ocena |
|---|---|
| Jakość architektury | 9.5/10 |
| Gotowość produkcyjna (po drobnych poprawkach) | 8.5/10 |
| Czas wykonania | 6 minut |
Test 3: Debugowanie race condition w mikroserwisach
Prawdziwy przypadek z produkcji: intermitentny błąd — raz na 1000 żądań transakcja nie była zapisywana poprawnie. Nasz zespół szukał przyczyny przez 3 dni, mając dostęp do logów, kodu i pełnego opisu architektury.
Zadanie: „Analizując te logi i kod, zidentyfikuj przyczynę race condition w systemie płatności. Zaproponuj rozwiązanie.”
W ciągu 2 minut Claude wskazał precyzyjnie: brak odpowiedniego poziomu izolacji transakcji w PostgreSQL połączony z nietransakcyjnym zapisem do kolejki Redis. Zaproponował wzorzec Outbox z implementacją kodu. To było dokładnie to, co powodowało błąd.
| Kryterium | Ocena |
|---|---|
| Trafność diagnozy | 10/10 |
| Jakość proponowanego rozwiązania | 9/10 |
| Czas analizy | 2 minuty (vs 3 dni zespołu) |
Test 4: Wsparcie dla Rust, Go i Elixir
Sprawdziliśmy też języki, w których modele AI często halucynują albo generują poprawny składniowo, ale semantycznie bezsensowny kod.
| Język | Ocena | Uwagi |
|---|---|---|
| Rust | 9.5/10 | Borrow checker i lifetimes — bez halucynacji |
| Go | 9/10 | Goroutines i channels — kod idiomatyczny |
| Elixir | 8.5/10 | Rozumie actor model, nie tylko składnię |
Jakość generowania tekstu i copywritingu
Styl i naturalność odpowiedzi
GPT-5.4 bywa jak dobrze napisana encyklopedia — rzetelna, ale trochę zimna. Claude Sonnet 4.6 utrzymuje bardziej konwersacyjny ton i lepiej dostosowuje styl do kontekstu: formalny w dokumentacji, swobodny w brainstormingu. W praktyce testowaliśmy: dokumentację techniczną (świetnie), posty na LinkedIn (naturalny ton, bez korporacyjnej papki), maile do klientów (dobrze, choć czasem lekko zbyt grzeczny), artykuły eksperckie (świetnie — głęboka analiza, nie tylko streszczenie).
Przestrzeganie instrukcji — tutaj Claude nie ma sobie równych
To obszar, w którym różnica jest najwyraźniejsza. Claude wykonuje szczegółowe instrukcje z niezwykłą dokładnością. Poproś o artykuł „maksymalnie 800 słów, z nagłówkiem H2 co 200 słów, bez słowa 'rewolucja’, z trzema przykładami” — i dostajesz dokładnie to. GPT-5.4 często próbuje być pomocny na swój sposób, zamiast ślepo realizować wytyczne.
Prosty test porównawczy: streszczenie artykułu w dokładnie 150 słowach.
| Model | Liczba słów | Odchylenie |
|---|---|---|
| Claude Sonnet 4.6 | 149 | −1 |
| GPT-5.4 | 167 | +17 |
Drobnostka? Nie dla kogoś, kto automatyzuje procesy contentowe i liczy na przewidywalny, powtarzalny output.
Claude Code: terminalowy asystent do poważnej pracy
Czym jest Claude Code?
Claude Code to dedykowane narzędzie CLI od Anthropic — nie wrapper na API, ale pełnoprawny agent. Może przeglądać strukturę plików, czytać i edytować kod, uruchamiać testy, wykonywać komendy shell i commitować zmiany do Git. Wszystko z terminala, bez przełączania okien.
Test w realnym projekcie
Dodanie funkcji wyszukiwania do istniejącej aplikacji Django. 15 minut od startu do działającego kodu z commitowanymi zmianami:
- Analiza struktury projektu — modele, widoki, URL-e
- Identyfikacja potrzebnych zmian w modelach
- Wygenerowanie migracji
- Stworzenie widoków i szablonów
- Napisanie testów pytest
- Uruchomienie testów, znalezienie 2 błędów, auto-fix
- git commit z opisem zmian
To najlepsze doświadczenie pair programmingu z AI, jakie mieliśmy. Jak siedzenie obok doświadczonego seniora, który zna projekt i nie wymaga tłumaczenia od podstaw.
Ceny i dostępność Claude Sonnet 4.6
Plany subskrypcyjne
| Plan | Cena | Co dostajesz |
|---|---|---|
| Free | $0 | Sonnet 4.6 z limitami wiadomości |
| Pro | $20/mies. | Priorytetowy dostęp, wyższe limity, early access do nowości |
| Team | $25/user/mies. | Współpraca zespołowa, panel administratora |
Ceny API
| Model | Input (1M tokenów) | Output (1M tokenów) |
|---|---|---|
| Claude Sonnet 4.6 | $3 | $15 |
| Claude Opus 4.6 | $15 | $75 |
Sonnet jest droższy w inputcie niż GPT-5.4 Standard ($3 vs $2,50), ale porównywalny z GPT-5.4 Thinking. Biorąc pod uwagę jakość w zadaniach programistycznych, ta różnica jest uzasadniona. Dla 95% zastosowań Sonnet wystarczy — Opus to wersja dla absolutnie najtrudniejszych zadań i jest znacząco droższy.
Wady i ograniczenia
- Brak natywnego dostępu do internetu — w przeciwieństwie do GPT-5.4 i Grok, Claude nie może samodzielnie przeszukiwać sieci
- Mniejszy ekosystem — biblioteka integracji i gotowych rozwiązań wciąż ustępuje OpenAI
- Bywa nadmiernie ostrożny — zdarza się, że odmawia wykonania nieszkodliwych zadań ze względu na polityki bezpieczeństwa
- Wolniejszy w godzinach szczytu — na darmowym planie odczuwalne opóźnienia
Podsumowanie: dla kogo Claude Sonnet 4.6 jest najlepszym wyborem?
Claude Sonnet 4.6 to aktualnie najlepszy model na rynku dla programistów full-stack i backend, zespołów technicznych tworzących dokumentację, firm potrzebujących niezawodnego asystenta do code review i refaktoryzacji, oraz każdego, kto potrzebuje precyzyjnego przestrzegania szczegółowych instrukcji.
Jeśli Twoja praca polega na kodowaniu, debugowaniu lub tworzeniu dokumentacji technicznej — Claude Sonnet 4.6 jest w tej chwili najlepszym dostępnym narzędziem. GPT-5.4 pozostaje lepszy w zastosowaniach ogólnych i ma bogatszy ekosystem. Ale dla programistów wybór jest oczywisty.